What Does “Machine Learning” Mean? Random Forest Walk, Linear Regression, and Other Common Algorithms
What is Machine Learning?
To start with a quick background - machine learning is programmed artificial intelligence that is given the task of teaching a given program to teach itself. To elaborate a little further, machine learning is a subset of AI that can self-learn using a variety of techniques. It can do so using data that it has collected from previous experiences, or it can self -learn using general data that a programmer can feed it. There are many ways for a machine to learn from data, but we’ll go over the big (and easy to understand) ones in this paper. You’ll find that the way machine learning works can be distilled quite easily into “the act of using statistics and large datasets to teach a machine to draw inferences/patterns”. The world of data science is at least as deep as the ocean, but for this post, let’s do some surface-level exploration.
Types of Machine Learning
There are three main types of machine learning. Two of the types overlap with the types of learning in neural networks, as they are similar concepts - that is, supervised learning and unsupervised learning. The first type, supervised learning, essentially works as such: if the computer makes a conclusion, there is a separate function other than the decision-making one - a supervisor, if you will - that tells the computer if it made the correct choice, or the incorrect choice. More specifically, the program will take an input, take the expected output, then compare its own output with the expected output to decide if it is right or wrong - and how far off or how on the money the program was. The expected output is usually achieved by feeding the computer examples; e.g. a picture of an apple labelled “apple”. This type of machine learning can calculate its own error and adjust accordingly so it can do a better job achieving the right answer in the future. The second type of learning, unsupervised learning, will have the tools to take in multiple inputs, such as geometry, pixels, or color, and try to find a pattern within them and cross-reference its past history with similar inputs. Using the machine’s “memory” which is actually just an aggregate of data and right/wrong answers, the machine will make a conclusion. Using this method, the machine can also teach itself and become more intelligent over time. The last “main” type of machine learning is reinforcement learning, which is quite different from supervised and unsupervised learning. This type of learning is essentially learning through mistakes. If you put a mouse in a maze, and simply give the mouse some water if it does the right thing, and a small shock if it hit a wall, it will eventually learn how to navigate the maze. By reinforcing the machine’s learning, it is the equivalent of giving the mouse water or a shock. The machine must learn on its own with minimal human intervention, but it will take some time.
Common types of models used by Data Scientists
There are many types of algorithms used by machine learning, from random forest algorithms to KNNs. We’ll start with two of the most prevalent ones before we go into a more complex model: linear regression algorithms and logistic regression algorithms. Linear regression models are used to estimate real value based on the averages of continuous variables. For example, estimating the price of a house based on a line of best fit for the prices of other houses with similar square footage.

The line of best fit is represented here by Y = a*X + b.
The next type is a logistic regression model, which estimates binary values - also known as true/false, or 1/0. It does this by analyzing the probability of an event by fitting the data to a logit function. Its output is always 0 or 1.
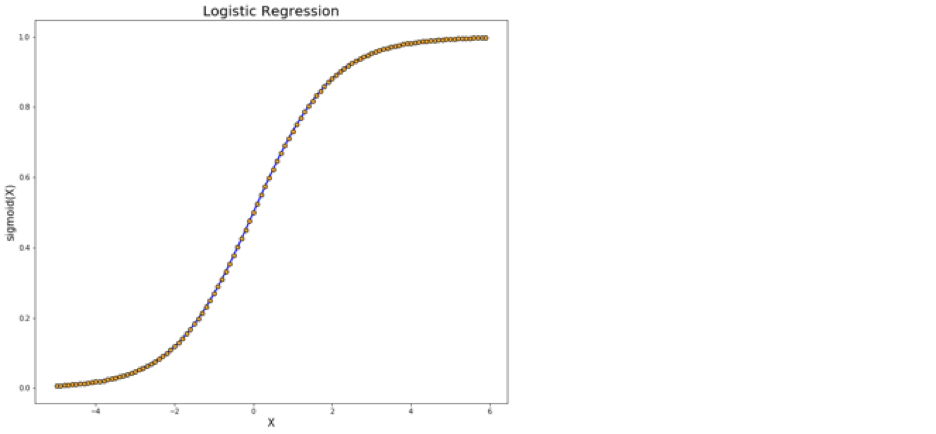
Machine learning is, at the end of the day, simply statistics! Regression models are used to allow an algorithm to learn from a large dataset and, using statistical correlation techniques such as the ones mentioned in my previous post (and likely the next post). Now, let’s look at a more complex/interesting algorithm: the random forest.
Decision Trees & the Random Forest Algorithm
Not to keep leading you on or anything but to understand the random forest algorithm, we must first start with decision trees. This is because all a random forest algorithm really is, is an aggregate of decision tree models. I’ll keep it brief, I promise.
Decision trees require you to start with a question, for example: Is the weather okay for tennis today? Then, like a waterfall there are subsequent questions to ask such as: “what’s the weather outlook say?”, If it’s rainy - “what’s the wind like?” or “Is the humidity higher than usual?”. Decision tree models are intended to find the best possible way to split the aggregated data. They’re usually a supervised learning algorithm. The problem, however, with using decision trees for something that needs accuracy is that they’re notoriously vulnerable to bias and over-fitting. To solve this, enter the random forest algorithm

Decision trees are, you guessed it, a supervised learning algorithm. The problem with using decision trees for a task arises when one needs accuracy - these models are notoriously vulnerable to bias and over-fitting. To solve this, enter the random forest algorithm.
Regression or classification are the name of the game for random forest algorithms. There are 3 parameters which serve as the basis for the parameters of a random forest model. Node size, # of features, and # of nodes. Now, it’s a common trope among data scientists that if you have a problem with your model you just throw more models at it. The random forest algorithm takes this to another level, as it’s really at its heart, an amalgamation of decision trees.

Each individual tree is made up of a dataset that can be referred to as the training wheels for our algorithm. ⅓ of the data is randomly chosen to be used as test data, to add an element of random-ness. There are more ways that a random forest algorithm uses randomness to its advantage, but this post is already a lot longer than I intended and I don’t want to bore you - the prized reader - with too many details. The “sum of” (as seen in the above figure) the amalgamation of decision trees are in most cases averaged out, and a sort of messed-up democracy takes place where the majority vote yields the desired outcome. This significantly decreases the risks decision trees posed by ensuring much less overfitting due to the sheer number of total decision trees a random forest model is comprised of. It’s also more accurate with large datasets - usually to a great degree. However, I’m sure you can see why the random forest model is also quite slow to use and not at all resource-efficient.
Until next time,
Khalil (TheStatsGuy)